

「AIアバター」と聞いて思い浮かべるのは、まずHeyGenやD-IDといったツールだろう。だがここ数カ月でよく名前を聞くようになったのが、Tavus(タバス)だ。
「写真1枚でリアルなAIヒューマンが作れる」という新機能を発表し、業界内でにわかに注目が集まっている。
正直なところ最初は「どうせよくある口パクアバターでしょ」と思っていた。調べてみたら、想像していたものとはかなり違った。Tavusが目指しているのは単なる動画生成ではなく、「AIヒューマン」という新しいコンピューティング層を作ることだった。
この記事では、Tavusが何者なのか、2026年の新機能「Image-to-Replica」が何を変えるのか、料金や使い道まで整理する。
・Tavusとは何か・他のAIアバターツールとの違い
・2026年最新機能「Image-to-Replica」の仕組みと使い道
・料金プランと「無料で何ができるか」
・向いている人・向いていない人
Tavus(タバス)とは?
「動画を量産する」から「AIヒューマンを作る」へ
Tavusは2020年創業のスタートアップで、自社を「ヒューマン・コンピューティング・カンパニー」と称している。
当初の主力サービスは、1本の動画を撮影するだけで何千通りものパーソナライズ動画を自動生成するツールだった。たとえば営業担当が一度だけ自己紹介動画を録画すれば、Tavusのシステムが各顧客の名前・会社名・購買履歴を組み込んだ個別動画を量産してくれる。
しかし2025〜2026年にかけて、Tavusの方向性は変わった。「大量の動画を作るツール」から「リアルタイムで会話できるAIヒューマンを作るプラットフォーム」へとピボットしたのだ。
現在、Tavusのプラットフォームは10万人以上の開発者が利用しており、Amazon・Deloitte・EY・Mayo Clinic・Salesforceといった企業での導入実績がある。2024年3月にはシリーズAで1,800万ドルを調達し、今も急成長中だ。
2026年最新機能:Image-to-Replica とは
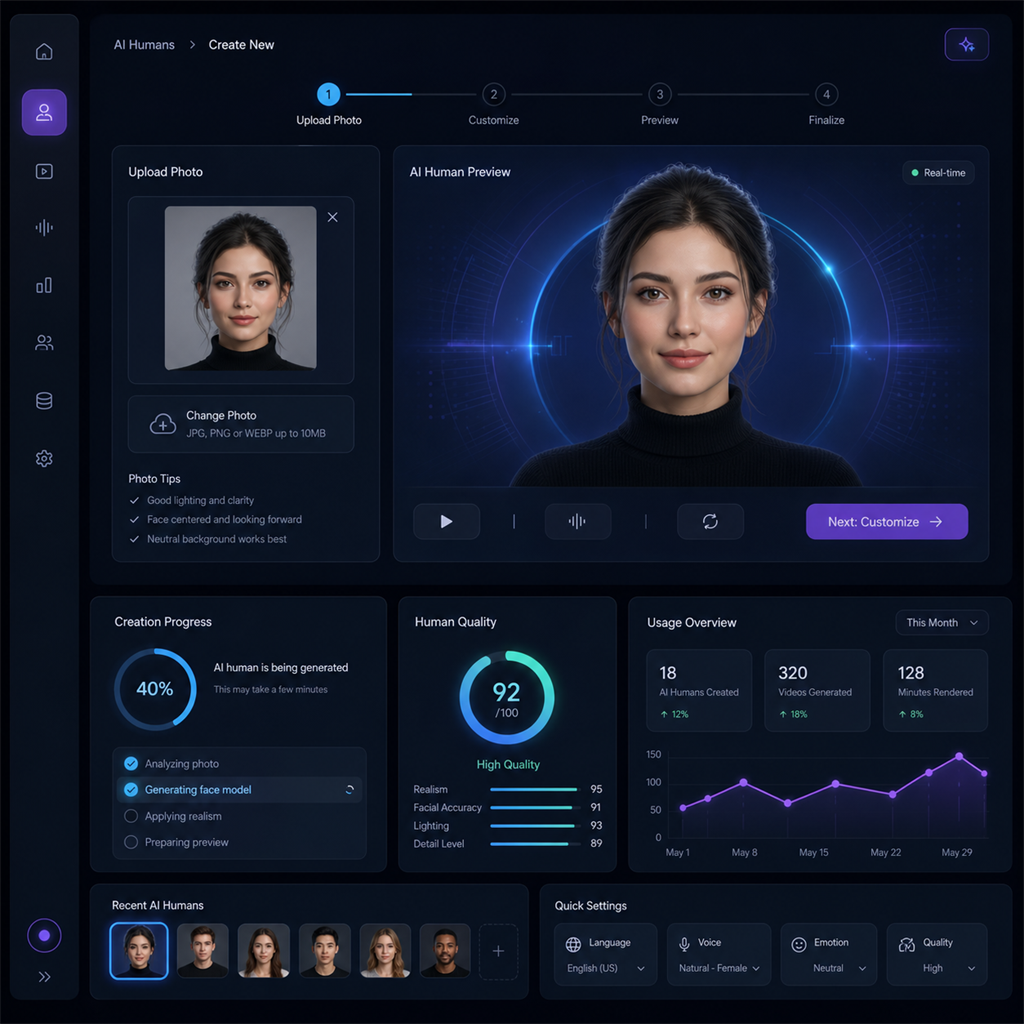
写真1枚でリアルなAIアバターが「会話する」仕組み
これまでTavusでAIアバター(Replicaと呼ばれる)を作るには、30秒〜数分のビデオ録画が必要だった。
Image-to-Replicaはその前提を崩した機能だ。静止画1枚から、リアルタイムで会話できるAIヒューマンを生成できる。
処理の流れはこうだ。
- 画像をアップロードすると、顔の向き・照明・遮蔽がないかを自動評価
- 問題がある場合は「Fix with AI」ボタンで自動修正
- モーション制御のビデオ拡散技術で、静止画から「話す・聞く動作」を合成
- 合成動画をPhoenix-4モデルに学習させてAIヒューマンが完成
写真から動く映像を生成するだけでなく、そのアバターがリアルタイムの会話に対応できる点が従来ツールとの大きな違いだ。
Phoenix-4 モデルが実現したこと
Image-to-Replicaを支えているのが、Tavusの最新モデル「Phoenix-4」だ。
Phoenix-4の特徴は一言で言うと、「感情とリスニング動作をリアルタイムで制御できる最初のモデル」であること。具体的には:
- ミリ秒レベルの低遅延でリアルタイム応答
- 感情状態・うなずきなどのアクティブリスニング行動を自動生成
- 会話の文脈を認識して表情や頭の動きを制御
- ビデオ収録で作成したAIアバターと同等の品質を写真から再現
以前の動画AIアバターは「喋っているだけ」に見えた。Phoenix-4は「ちゃんと話を聞いている」ように見える。この差が、リアル感に直結している。
Tavusの主要機能3つ

① パーソナライズド動画生成(従来の主力機能)
顧客リストと変数(名前・会社名など)を読み込ませると、個別対応の動画を一括生成する機能。営業・採用・カスタマーサクセスでの活用が多い。
「30分かけていた個別動画制作が5分で完了した」という事例が海外の導入企業から報告されている。1本の録画から何千本もの動画を自動量産できるスケーラビリティが強みだ。
② 会話型ビデオインターフェース(CVI)
AIヒューマンとリアルタイムでビデオ通話できる機能。Zoomのような画面で、AIアバターが視覚・音声・文脈を認識しながら応答する。
Mayo ClinicやCVSのような医療機関が患者説明動画への活用を進めているのは、この機能があるからだ。30言語以上に対応しており、日本語も含まれる。
③ Image-to-Replica(2026年新機能)
前述の通り。特にユニークなのは、写真が「実在の人物」でなくていいという点だ。
- ブランドのロゴに長年登場し続けたマスコットキャラクター
- AIが生成したイラストキャラクター
- 歴史上の人物(メモリアル・教育用途)
これらのキャラクターが、写真1枚からリアルタイムで会話できるAIヒューマンになれる。
料金プラン
| プラン | 月額(目安) | 主な内容 |
|---|---|---|
| Free | 0ドル | 基本機能の試用・APIアクセス(少量) |
| Starter | 59ドル 〜 | カスタムレプリカ作成・動画生成 |
| Growth | 397ドル 〜 | チーム向け・大量動画生成 |
| Enterprise | 年額12,000ドル〜 | カスタム対応・SLAあり |
※ 2026年5月時点の情報。公式サイトで最新料金を確認のこと。
無料プランでできること: APIアクセスと基本的な動画生成の試用はできる。ただしカスタムレプリカ(自分・自社ブランドのアバター)を作るにはStarterプラン以上が必要だ。
「まず試してみたい」という段階であれば無料で十分だが、実業務で使うなら月59ドルのStarterが最低ラインになる。
こんな人・企業に向いている / 向いていない
・動画コンテンツを大量に個別対応で作りたいマーケター・営業チーム
・ブランドマスコットやキャラクターをリアルに「動かしたい」企業
・AIアバターをアプリやWebに組み込みたい開発者
・多言語対応の動画接客を低コストで実現したい企業
・動画を1〜2本だけ作りたい個人(コスパが合わない)
・高品質なCGアニメーション映像を求めている(映像品質は用途特化)
・API統合なしで直感的に使いたい非エンジニア(学習コストがある)
まとめ
Tavusを調べ始めたとき、「HeyGenと何が違うんだろう」と思っていた。
調べてわかったのは、Tavusはそもそも「動画を作るツール」として設計されていないということだ。目指しているのは、AIが人間の代わりに「見て・聞いて・答える」という新しいコンピューティング体験を作ることだ。
Image-to-Replicaは、その野心を写真1枚で実現した機能だ。実在しなかったキャラクターや触れることのできなかった人物が、AIヒューマンとして会話できるようになる。
まずは無料プランでAPIを試してみるだけでも、このツールが何を変えようとしているかは体感できると思う。


コメント